越来越多的数据库开始暴露 GraphQL 接口,从搞关系式数据库的 postgraphql 到弄图论数据库的 Neo4j-GraphQL Extension。
你只需要用 GraphQL Schema Defination Language 描述出你的业务模型,一个 GraphQL API 就从数据库上暴露了出来,接下来只需要在客户端写一些 query 就可以在很短的时间内搞定前后端交互……
等等,这样难道不像把 SQL 语句从前端发送到后端执行一样傻么?
我们还缺少一个鉴权层,缺少一个挡在数据库前的网关,至少执行以下两个步骤:
- 确认用户身份,可信地把用户定位到图里的一个节点
- 给客户端发来的 GraphQL 查询加上鉴权操作,判断用户节点是否拥有查看他想看的每个节点的权限
这两个步骤一定得在服务端完成,不然用户就可以构造出 AND 1=1 这样的伎俩来欺骗我们。
也就是说,我们需要一个能反向代理、并对 query 做一定修改的,级联的 GraphQL 网关。
权限管理模型
为了方便,我将参考 Palantir 经过实战检验的访问控制模型 [2] ,并以 Neo4J 作为存储数据的后端。
基本访问权限控制
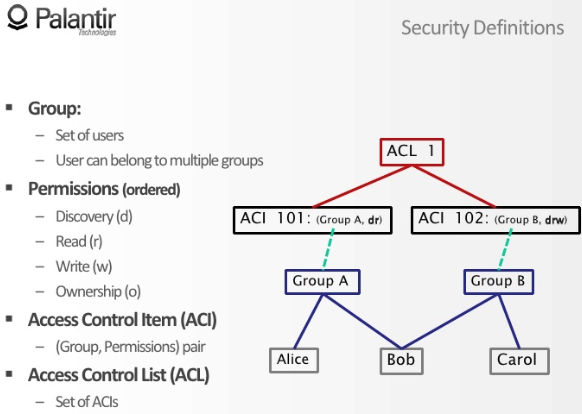 每个确认身份的用户会归于一个或多个用户组,例如 Bob 同时处于 Group A 和 Group B。
每个确认身份的用户会归于一个或多个用户组,例如 Bob 同时处于 Group A 和 Group B。
而每个用户组会一对一地关联到一个访问控制条款(Access Control Item)上,也就是说 ACI 101 只描述了 Group A 的权限,ACI 102 只描述了 Group B 的权限 B。
最后我们把多个访问控制条款(ACI)总结为一个访问控制表(Access Control List),以便批量修改多个用户组对某一条信息的权限。
注意到访问控制条款描述了四种访问权限(d r w o):
- 可感知:搜索一个电话号码时能搜到它存在,但不知道是谁的;查看某个人档案时能知道他有一个属性是电话号码,但不知道是多少。你可以搜到一条建议「如果你想知道更多,请联系鹳狸猿 blabla……」
- 可读:能搜到、能看到值
- 可写:能搜到、能看到值、能修改值
- 完全拥有:能搜到、能看到值、能修改值、能修改元信息(例如调整某个属性的某个数据来源记录对应的访问控制表)
对于一条信息,没有上述任意一种权限的用户就不可能以任何方式感知到知识的存在,也没法通过随机 ID(可能类似于 Facebook Relay 的 Base64 Global ID 实现)、时间信息等推理出一条信息的存在。
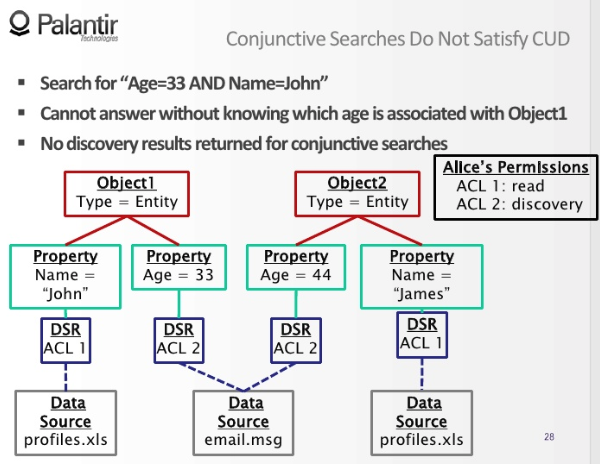 而数据库中实体的每条属性都是一个节点,这些属性都是从某个资源文件中提取出来的。例如 Name: ‘John’ 就是从 profiles.xls 中提取出的数据。且可能有多个资源文件都包含实体的这个属性,从而能做一致性验证或共指消解。这种和多个数据来源记录相连的属性节点,只要你有任何一个数据来源记录的读权限,你就能看到这个属性节点。
而数据库中实体的每条属性都是一个节点,这些属性都是从某个资源文件中提取出来的。例如 Name: ‘John’ 就是从 profiles.xls 中提取出的数据。且可能有多个资源文件都包含实体的这个属性,从而能做一致性验证或共指消解。这种和多个数据来源记录相连的属性节点,只要你有任何一个数据来源记录的读权限,你就能看到这个属性节点。
拦在属性节点和访问控制表中间的,是数据来源记录(Data Source Record),它会关联到一个访问控制表(ACL)。如果你的用户所在的任何一个用户组,关联到的访问控制表,正好也关联到这个数据来源记录,你就能看到数据来源记录连着的属性节点。
你可能会在一段时间内因为参加陪审团而加入某个用户组,从而你所在的(ACL)能看到某个数据。但是随着案件的结束,这个用户组就会被取消掉。
如果我的理解正确,实现这个模型后我们就可以把 GraphQL API 暴露在公网下,没有足够权限的用户没法通过权限内的零碎数据推理出权限外的知识(例如搜索「年龄三十三岁且名字叫 John 的人」的搜索结果应该和搜索「年龄三十三岁的人」是一样的)。而且得益于数据的图结构,对数据访问权限的修改会立即对所有相关用户生效,毕竟用户沾沾自喜的所谓的权限,只不过是图上指向数据的一根指针而已。
更多条件限制
有一些敏感数据,在查看前需要用户表明他们的查看行为是有正当理由的,就像警察逮捕你必须要出示证件一样,这种对正当理由的要求称为基于断言的访问限制(Predicate-based access restrictions)。[3]
在 Palantir 的系统上,当你搜索自动车牌扫描器(ALPR)的数据时,你需要提供你的调查类别(investigation categories?)或你正在执行的公安系统案件编号,来确认你是在执行公务。这个断言就是一个返回 boolean 的函数,所以你工作的时间、地理信息也可以被纳入考虑,所以只有某个州参与此次案件的公安干警才能访问这些数据。
提醒删除
数据库中存在只在一定时间内有用,或版权在一定时间后会过期的数据。为了减小认知过载、同时保护版权方权利,Palantir 可以设置在一段时间后提醒数据的所有方,是否要为数据续期,不然就要被删掉了。[3] 删除分为四种方式:
- 归档:修改元信息,去掉一些用户组的访问权限(securely locked-down and/or restricted storage of older or more sensitive information)
- 去共指消解:将部分来源的隐私信息与具体人物分离(Anonymization and de-identification of personally identifying records)
- 软删除:前端从 API 无法获取数据,但后端直接操作数据库还是可以读到。
- 硬删除:从数据库里抹掉
取舍
但是条件限制和删除提醒的具体机制不明,所以为了简化问题,我们暂时不会予以考虑,在本文中我们只实现基于 ACL 和 DSR 的部分。
植入鉴权操作
对于我们之前提到的这两个步骤:
- 确认用户身份,可信地把用户定位到图里的一个节点
- 给客户端发来的 GraphQL 查询加上鉴权操作,判断用户节点是否拥有查看他想看的每个节点的权限
第一部分,我们可以通过 Redis 等缓存服务将 token 转换为 Neo4J 中的用户 ID。用户发来的 query 可能是这样的:
# 获取自己提过的问题
query MyQuestion($token: String!, $title: String!) {
Question(token: $token, title: $title) {
title
answers
}
}
在网关服务器上,我们在 Question 的 resolver 里去调 Redis,把 token 转换成 User ID,作为转发给 Neo4J 的时候带的参数。
然后我们描述一下找到 title 这个 Property 需要经过的路径,由于黑路白路只要能走到 Property 就是好路,我们找的是各种路径之间「或」的关系,所以只需要在 query 的外层包裹上几层,遍历下图中所有鉴权相关节点即可:
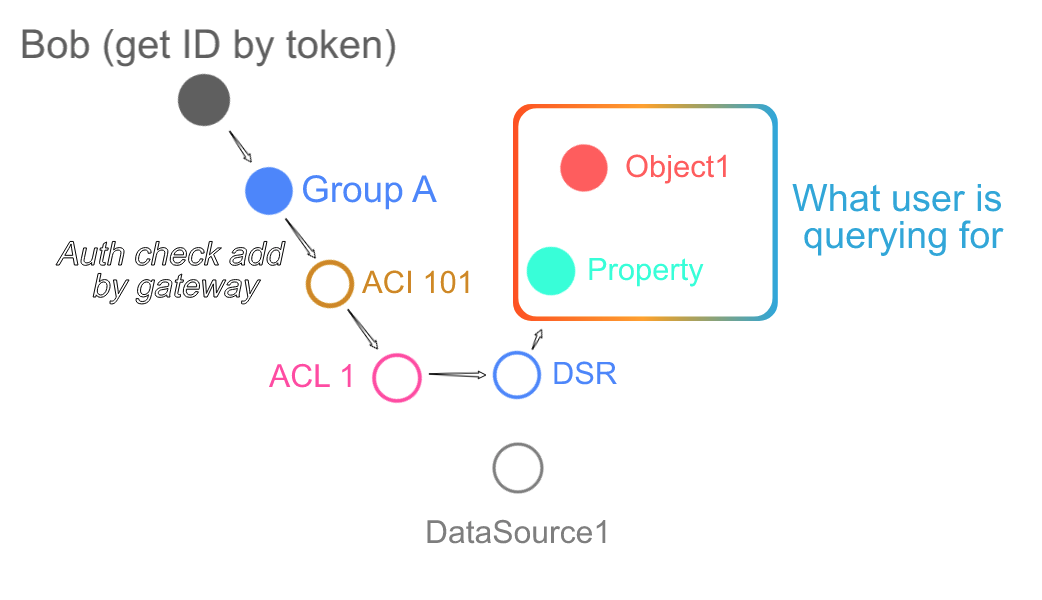
这样检查你有没有权限看 answers 很简单,只需要套一个模板。转换后得到一个 Permission Query:
query MyQuestionPermissionQuery($ID: ID!, $title: String!) {
User(ID: $ID) {
Groups {
title_dr_ACI: ACI(permission: "dr") {
ACL {
DSR {
Property(key: "title", value: $title) {
Object(type: "Question") {
ID
}
}
}
}
}
answers_dr_ACI: ACI(permission: "dr") {
ACL {
DSR {
Property(key: "answers") {
Object(type: "Question") {
ID
}
}
}
}
}
title_r_ACI: ACI(permission: "r") {
ACL {
DSR {
Property(key: "title", value: $title) {
ownerInfo
Object(type: "Question") {
ID
}
}
}
}
}
answers_r_ACI: ACI(permission: "r") {
ACL {
DSR {
Property(key: "answers") {
ownerInfo
Object(type: "Question") {
ID
}
}
}
}
}
}
}
}
这样 Neo4j 会匹配所有可能的 Groups 下,经过符合权限的 ACI 能到达的 Property。
我们会得到一个多层数组,经过 flattten(lodash)过后我们看看 Object ID 是不是一致的,一致就说明我们对于这个 Object 连接的两个 Property 都有读权限,如果其中一个没有,就返回 ownerInfo 信息。然后我们对于有读权限的 Property 再发一次查询,取得它们的数据。
其实上面这个超长 Permission Query 用 Cypher 描述可以一次搞定:
MATCH
(u:User)-[...]->(p1:Property {key: "title", value: $title})->(o:Object)->(p2:Property {key: "answer"}),
(u:User)-[...]->(p2) // 但我们没法在一次查询里用 GraphQL 表达出这种 AND 关系
...
可惜 GraphQL 没法在一棵查询树里做变量绑定,比如上面的 p2 在 GraphQL 里就没法绑定到一个变量上,所以 GraphQL 查询没法描述所以有向无环图。
根据 Graphcool 的实践经验,虽然 Mutation 要在网关检查了 Permission Query 之后才能发送给数据库,但是读数据的时候 Permission Query 和 Data Query 可以由网关并行发给数据库。
我们还会生成一个 Data Query,用于从 Neo4j 里取数据:
query MyQuestionDataQuery($ID: ID!, $title: String!) {
User(ID: $ID) {
Groups {
title_dr_ACI: ACI(permission: "dr") {
ACL {
DSR {
Property(key: "title", value: $title) {
value
}
}
}
}
answers_dr_ACI: ACI(permission: "dr") {
ACL {
DSR {
Property(key: "answers") {
value
}
}
}
}
}
}
}
可以看到它和用户发到网关的 query 长得很不像,因为我们通过修改 Schema 对客户端隐藏了 ACL、DSR 等细节,并骗客户端说我们所有的 Property 都是保存在 Object 里的哦,其实并不。
对于 Mutation,比如我们想要添加一篇文章,首先把具体文本存到某个 URI 处,然后往 Neo4J 里添加元信息,即:
CREATE (d:Document)<-(p:Property {key: "URL", value: "xxx"})<-(:DSR)<-(:ACL)<-(:ACI)<-(:Group)<-(:USER)
通过修改 AST 转换 GraphQL Query
那么如何从客户端发来的 query 生成 Permission Query 和 Data Query 呢,很容易想到通过遍历抽象语法树来提取必要的信息。我们没必要使用 Antlr4 这样的解析器生成器,因为 graphql.js 为我们提供了这些信息,通过 resolver 的 info 参数传入,这个参数很少被用到,文档也基本没有,不过它提供了当前字段的 AST,我们来尝试使用它。 [6]
反向代理自省
GraphQL 的自省功能能让我们看到每个类型下面有哪些字段。对于某个实体上用户没有 discover 权限的字段,我们依然要告诉用户「这种类型的实体上就是有可能有这个字段,只不过你请求的时候它可能是一段关于你可以联系谁来请求权限的话」。所以对于每一个字段,它返回的值肯定是可空的,为空时可能会在 Error message 里告诉你联系 xx 管理员可以申请权限。
还有数据库里实际上实体和属性是分开的节点,是不同的类型,但面向 API 用户时我们要把实体的所有属性合并到这个实体的类型里,来使得自省功能被使用的时候,Object、Propertys 分离的做法是对用户透明的。
最简单的方法是请求 neo4j-graphql 生成的 schema:
{
__schema {
types {
name
kind
description
}
queryType {
fields {
name
description
}
}
}
}
用这个信息生成我们自己的 Schema 的话,我们要做的就只是删除我们不想让 client 看到的类型,生成只有一张只有 neo4j-graphql 中 schema 的子集的 schema,然后让 apollo-server 来提供自省。
对于我们的例子,情况比较简单,我们筛选出实现了 Object 接口的类型,然后请求所有连接到 Object 的 Property 类型的 key 作为 Object 的字段。(不大可能,所以还是不该用 key value,而应该用 key:value,然后实现各种类型的 Property?)
还需要把 Neo4J-GraphQL 的 Schema 和鉴权服务器的 Schema 合并,因为鉴权服务器(或者说网关服务器)还会提供一些别的 mutation,比如对图做一些比较复杂的定制化计算。
类型消歧:考虑 JSON-LD 方案
实例:用微信第三方认证鉴权
参考
Composing public GraphQL APIs Discussion
Palantir Access Control
Local Law Enforcement PCL White Paper - Palantir
baojie_iowa:privacypreserving-reasoning-on-the-semantic-web
Graphcool GraphQL Permission Queries Design series
Get Query info and execution state of the query by “info”
Getting IDL by introspection
There is a moduler state-of-art tool 「graphql-cli」,consider looking at it. It uses package 「graphql」’s buildClientSchema to build IDL .graphql file from introspection data.
