越加丰富的 JS 语法和丰饶的 npm 社区让我们能构建解决复杂问题的应用程序,随着 UI 自动化生成技术的进步,前端开发者面对的主要问题将不再是样式和动效的实现,而将是异构数据源融合、异步互联数据(Async Linked Data)的展示和交互方案设计。
我们考虑在前端输入结构复杂的数据,对数据推理并展示推理结果时,这样的系统很难做到大而全,每个用户都有自己的个性,他们会想看到应用有不同的主题、会想用自己喜欢的方式输入信息、会想要你的应用支持他偏门的用法。这些其实都不是问题,只要你提供了友好的插件(plugin or extension)系统,总会有能人志士做出贡献,写出牛逼的插件。
我们在设计前端应用时如果提早考虑到插件架构,能为我们的应用带来很大的社区活跃性。本文综述了目前比较流行的插件系统架构,供 Web 游戏开发者、信息管理系统开发者参考。
Semantic Media Wiki
用于构建 DBPedia 的维基百科,是使用一款叫 Media Wiki 的程序架设的。
Media Wiki 广泛用于各种维基站点,但它有一个缺点,就是没法细粒度地把百科页面语义化。维基百科每个页面就是一堆 HTML,当你有数百万个页面时,想找到某个实体就只能用信息检索(IR)的方法。当维基系统被 Semantic Media Wiki 插件接管,你就能通过搜索性别、年龄、职业来查找实体,就像使用一个数据库一样。可以说这个插件提升了用户(主要指维基维护者)生产、分享和使用结构化数据的能力。[2]
Semantic Media Wiki 作为 Media Wiki 的大型扩展插件集(expansion),在 Media Wiki 的框架上提供了很复杂的结构化数据、查询数据等功能,例如可以把维基内容变成图表、时间轴、地图等形式来展现。而它自身又可攻可受,自己是别人的插件,然后又提供了插件系统给别人。
例如 SMW 的插件 SemanticResultFormat 就可以丰富 query 结果的格式;SemanticForms 通过表单编辑(新的编辑方式)结合 SMW 进行操作,增强了「录入属性」这一部分,同时为 SMW 使用者提供了一个非常强大的函数 {{#arraymap}};Arrays 插件则为使用者提供了 {{#arraydefine}} 和 {{#arrayprint}} 两个函数。所以说 Semantic Media Wiki 是一个凸和凹的结合体,「泰卦」是也。[4]
TiddlyWiki
要考察用 JS 写就的插件系统的话,TiddlyWiki 的开发者文档[21]可不容错过,这是一个单 .html wiki 程序,所有的 Markdown 内容、JavaScript 插件都存储成了称为 tiddlers 的笔记。
例如 Markdown 会存放在 <div chapter.of="Microkernel Architecture" created="20140709110225227" modified="20140717213309369" sub.num="1" tags="doc new" title="Microkernel Description"> 这样的标签内,此 div 平时默认不显示,只有这个内容卡片被唤起时才加入到内容流里(非线性展现内容,如果没有实际用过则不易想象)。
插件脚本则存放在这样的标签内:
<script data-tiddler-title="$:/boot/boot.js" data-tiddler-type="application/javascript" type="text/javascript">/*\
title: $:/boot/boot.js
type: application/javascript
The main boot kernel for TiddlyWiki. This single file creates a barebones TW environment that is just sufficient to bootstrap the modules containing the main logic of the application.
On the server this file is executed directly to boot TiddlyWiki. In the browser, this file is packed into a single HTML file.
\*/
var _boot = (function($tw) {
/*jslint node: true, browser: true */
/*global modules: false, $tw: false */
"use strict";
大部分插件都是在 boot 后才被解析执行的,而且这些插件可以直接在 Tiddly Wiki 内编辑,毕竟这个插件代码的上半部分还有这这个插件的元信息,以注释的形式放在那里,等待 tiddly UI 的解读。
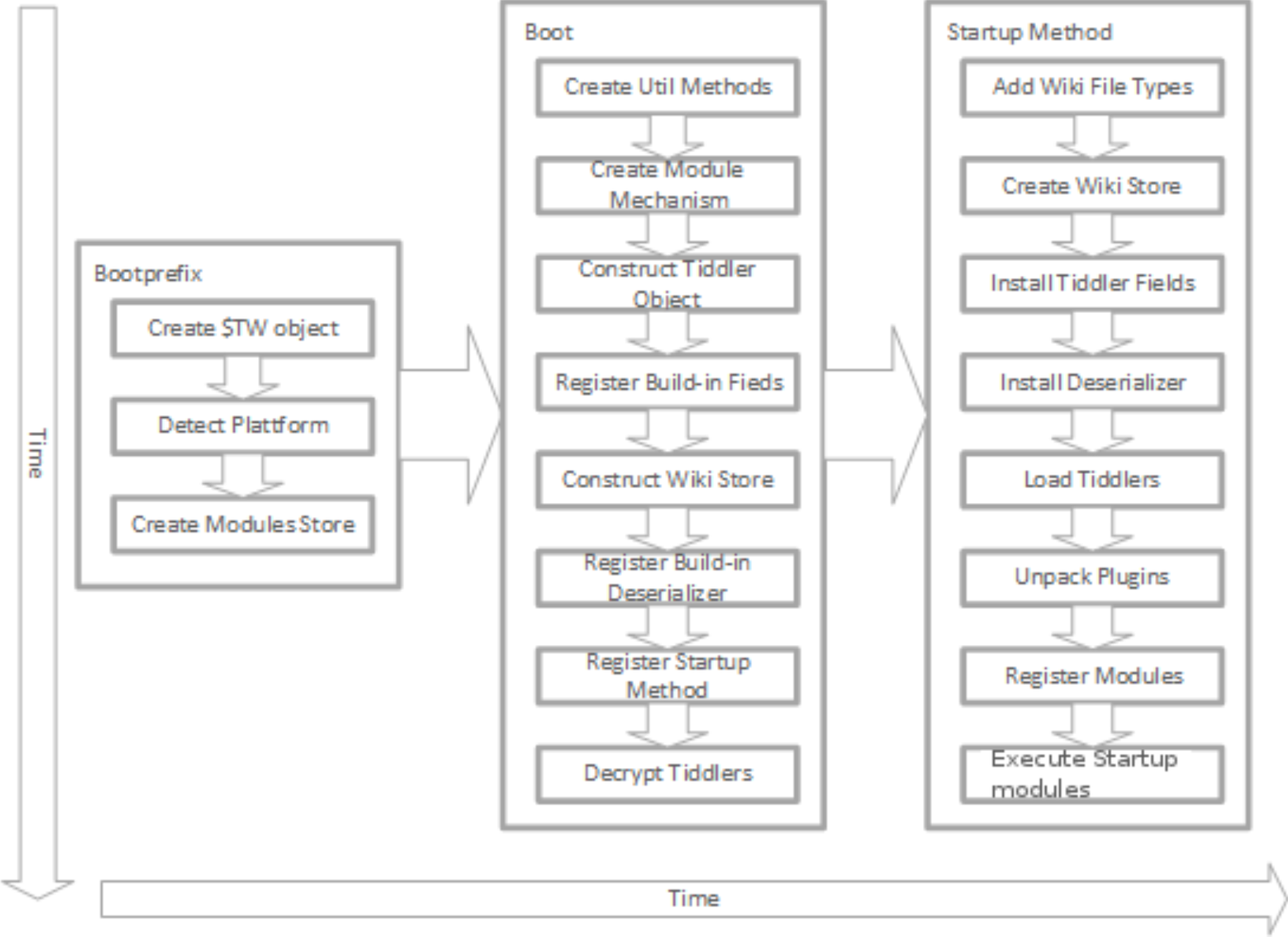
然后在用户打开 Tiddly Wiki 的 .html 文件的时候,首先运行一个称为 Microkernel 的启动引导程序,为这些插件提供基本的 API。
接着就是加载存储为文本的 Markdown tiddlers 还有存储为 "application/javascript" 的 tiddlers,这将会使用内置的 Deserializers。当插件加载后就可以使用一些 saver 或者 syncadaptors 插件了。
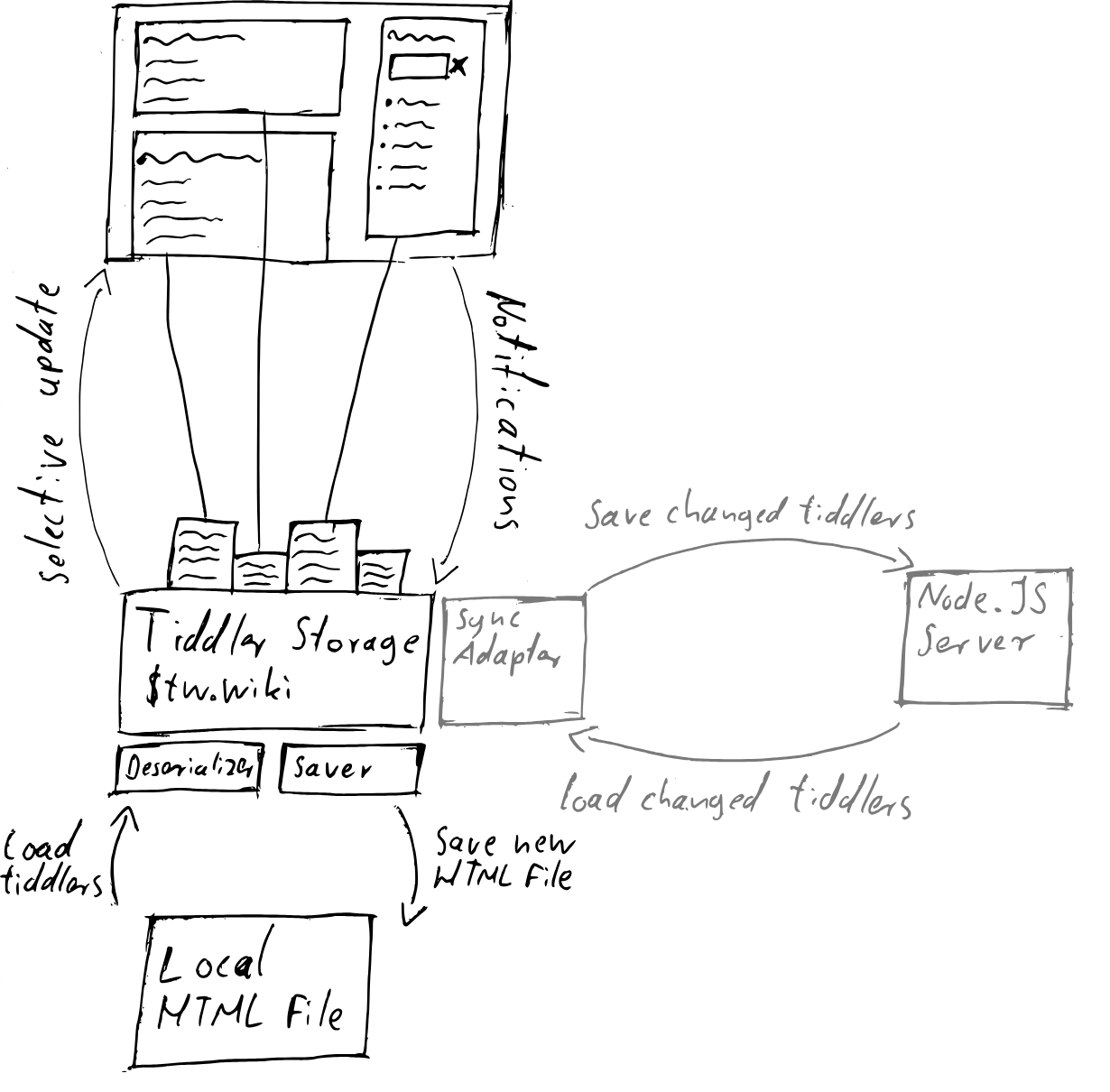
大部分的 tiddlers 一开始是处于反序列化后的状态的,例如这个和密码输入框有关的 UI tiddlers:
"$:/core/modules/commands/clearpassword.js": {
"title": "$:/core/modules/commands/clearpassword.js",
"text": "/*\\\ntitle: $:/core/modules/commands/clearpassword.js\ntype: application/javascript\nmodule-type: command\n\nClear password for crypto operations\n\n\\*/\n(function(){\n\n/*jslint node: true, browser: true */\n/*global $tw: false */\n\"use strict\";\n\nexports.info = {\n\tname: \"clearpassword\",\n\tsynchronous: true\n};\n\nvar Command = function(params,commander,callback) {\n\tthis.params = params;\n\tthis.commander = commander;\n\tthis.callback = callback;\n};\n\nCommand.prototype.execute = function() {\n\t$tw.crypto.setPassword(null);\n\treturn null;\n};\n\nexports.Command = Command;\n\n})();\n",
"type": "application/javascript",
"module-type": "command"
},
注意其中的 module-type: command,它说明了这个 tiddlers 的类型。这个 tiddlers 是由某个「插件」提供的。
我们在这部分里所说的「插件」和「tiddlers」的区别在于,「插件」里面可以带有好多个像上述那个一样的,反序列化后的 tiddlers,让安装插件的用户一次性获得好几篇 tiddlers。这些 tiddlers 是在运行时才反序列化成真正可执行的 js 的,在反序列化之前,这个「插件」就是一个 JSON Tiddler(注意上面代码结尾处的逗号,就是 JSON 的逗号)。
在运行时甚至可以创建一个 Tiddler 来存储当前的 UI 状态,就类似于 Redux Store 中的一个子 Store(所有的 Tiddler 存储在一个 k-v store 里,相当于 Redux Store)。通过允许这种分形 Tiddler(元笔记、元元笔记),Tiddly Wiki 的核心只需要提供与 Tiddler 相关的辅助函数就行了,剩下的事情都交给 Tiddler,交给社区。
下图中黑色边框内的深棕色的是核心插件,其他都是随后载入的。
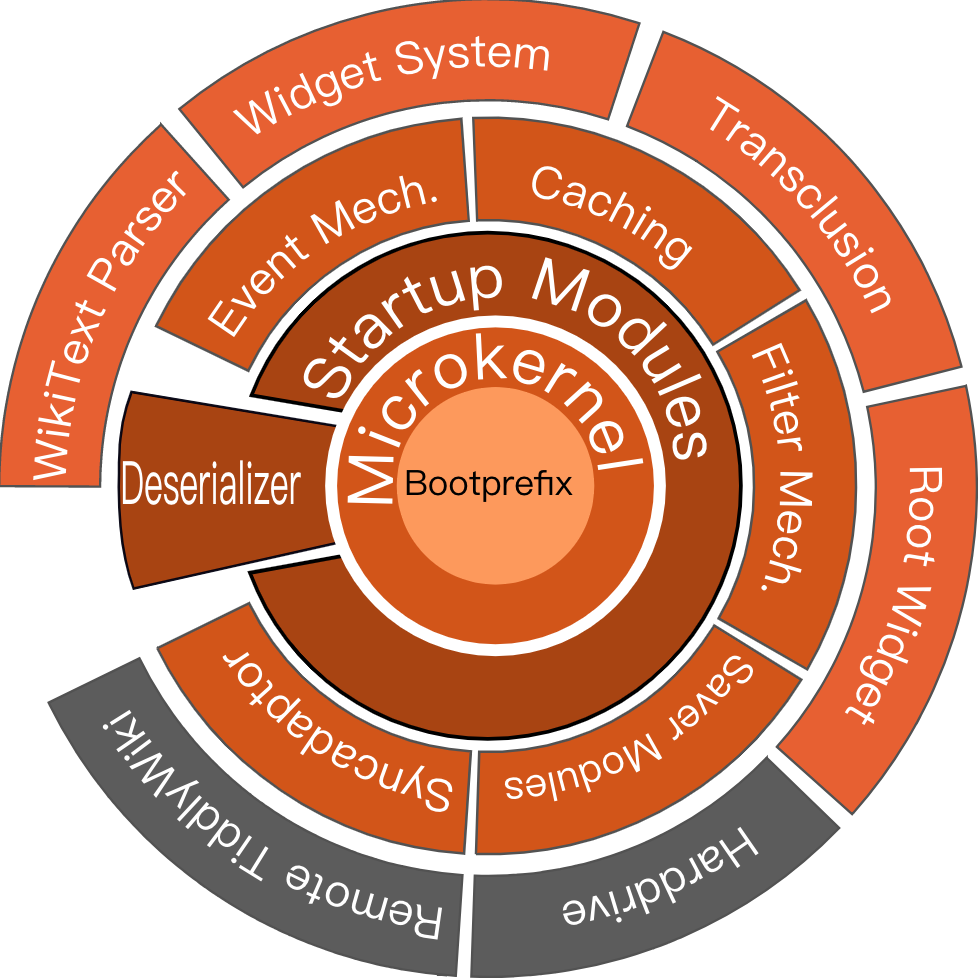
核心代码用这样的方式收集特定类型的含有代码的 tiddler:
// From boot.js:
// Gather up any startup modules
$tw.boot.remainingStartupModules = []; // Array of startup modules
$tw.modules.forEachModuleOfType('startup', function(title, module) {
if (module.startup) {
$tw.boot.remainingStartupModules.push(module);
}
});
// Keep track of the startup tasks that have been executed
$tw.boot.executedStartupModules = Object.create(null);
$tw.boot.disabledStartupModules = $tw.boot.disabledStartupModules || [];
// Repeatedly execute the next eligible task
$tw.boot.executeNextStartupTask();
forEachModuleOfType() 从已注册的含代码 tiddler(此时称为 module)中选择出类型为「启动参与过程」的那些,检查它是否符合 schema(是否暴露了 startup 函数),然后把它加到队列里,随后会被 executeNextStartupTask() 调用。
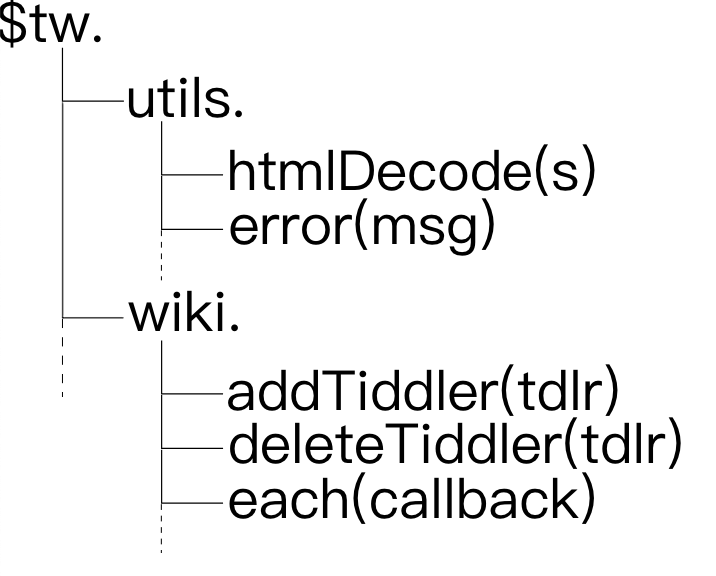
这让插件系统的 API 设计可以比较简洁,比如下面这几个例子都是围绕 tiddler 的常用 API:
$tw.Tiddler = function(/* [fields,] fields */)
$tw.Wiki.addTiddler = function(tiddler)
$tw.Wiki.deleteTiddler = function(title)
$tw.Wiki.getTiddler = function(title)
$tw.Wiki.forEachTiddler(callback, options)
this.wiki.addEventListener("change",function(changes) {
self.syncToServer(changes);
});
这种核心 API 设计起来当然没有什么难度,只需要把 $tw 变量挂到 window 或者 global 上即可。
但是如果 syncer tiddler 负责监听 change 事件等触发持久化操作,并把它转发到 saver 和 syncadaptor tiddler 上,这种非核心的 tiddler 之间的引用关系要怎么办呢,要怎么实现下面这种 API,以便支持 tiddler 之间的依赖关系呢?
var Widget = require('$:/core/modules/widgets/widget.js').widget;
// ...
ButtonWidget.prototype = new Widget();
大部分对其他 tiddler 的引用不是直接引用某个特定的 tiddler,而是请求某个类型的 module,这样允许社区开发者为某个过程加入新的实现。
接着 UI 相关的 tiddlers 会解析载入的 Markdown,如果是加密的就用内存中的密码先解密,然后把他们渲染成 Dom 元素,还有解析像是 [tag[learncard]topic[math]!tag[successful]] 这样的 wiki 内部 query。
当用户用编辑器插件对内存中的 Markdown 做出修改后,会有插件做脏检查,并更新相应的 Dom 元素。
把插件也看做内容管理系统中的普通文档是很极客的想法,适合应对多变的环境,比如遇到不顺手的场景就马上写一个小脚本来处理,有点 Emacs 的感觉。不过写插件一般来说还是个低频行为,大部分用户,包括 VSCode 的程序员用户,很多都应该是刚开始用的时候折腾插件,后来实际开始生产工作了,忙起来了就不会一直去折腾这些基础设施了。
代码笔记其实可以很好地代替插件市场,有分享方便、去中心化分发不受监管、核心功能都是笔记,更新系统的时候其实就只是从官方笔记里拉取几篇要更新的代码笔记等等优点。如果能做到安全可靠的话,会大大方便知识管理。
Load
我们一般会把第三方插件下载到文件系统上,放在名叫 /plugin 之类的文件夹里。
火狐狸浏览器的插件是 .xpi 文件,其实就是个 zip 包,下载到火狐存放插件的文件夹里之后,我们在内存里解压它,加载里面的脚本。一般来说这种直接把打好的包放进某个文件夹就能用的方式对使用者会比较友好,但系统设计会比较复杂。而且虽然简化掉了解压到文件系统的过程,但每次还是得在内存里解压读取内容。[3]
读取压缩包的好处是不用读取大量零碎文件。Atom 曾经为读取 node_modules 中数以万计的零碎小文件太慢而发愁,最后选择了读取 Electron 提供的 ASAR 归档格式,一次性读取海量小文件打包成的一个大文件。[2]
VSCode 的插件会依赖一些 npm 包,但当你点击 VSCode 某个插件的安装按钮时,VSCode 并不选择在此时去执行一次 npm i,而是劝插件作者在上传插件到市场之前提前 npm i 一下,然后把所有依赖打了包一起上传。
VSCode 的插件需要声明自己在什么样的情况下才被唤醒,例如当前打开的文件类型是 javascript 的时候,这样声明自己的插件就会被唤醒:
"activationEvents": [
"onLanguage:javascript"
]
或者一个颜色选择器可能会这样声明:
"activationEvents": [
"onCommand:extension.colorHelper.pick"
],
"commands": [
{
"command": "extension.colorHelper.pick",
"title": "Pick Color"
}
]
commands 里声明了一个 Action,把它绑定到 VSCode 按 command + shift + p 会出来的菜单里的一个按钮上,当这个按钮被按下,这个 Action 就会触发 onCommand:extension.colorHelper.pick 从而打开这个颜色选择插件。然后在插件里也能拿到这个 Action:message.command === 'pick',这样如果插件能被多种方式触发打开的话,在插件里也能做出判断,打开之后看到不同的功能。
上述的 activationEvents 和 commands 都在 package.json 的 contributes 字段里[12],VSCode 在启动时读取这些字段,在菜单里加上一些按钮、监听一些 Action,做好启动这个插件的准备但并不真正启动它,也不加载它的资源。
一篇值得阅读的源码是 C9 的 Architect.js,它展示了一个简单的插件系统,功能有:
- 读取 config 从而了解到要从哪些路径加载插件
- 加载插件的 JS 并分析插件的
consumes和provides字段,从而分析是否所有被依赖的插件都加载完了 - 在启动一个插件时先启动它依赖的插件,并把这些依赖项传到插件的 imports 里。
它有相当一部分的代码用在容错上。[7]
MediaWiki 的很多插件是在主程序启动时的钩子函数上加载,在启动时就运行加载太多东西会导致性能问题。此外 MediaWiki 在加入越来越多的钩子,以减缓主程序扩张的趋势。除了插件以外,MediaWiki 也可以通过 API 扩展功能,用浏览器上运行的 JS、桌面端的 Python 都可以自动化地进行人能用 MediaWiki 界面能进行的任何工作。
插件与内容的交互
对于前端应用来说,几乎整个应用都是可以受 JavaScript 控制的。Google Chrome 的插件可以在页面内通过 querySelector 拿到整个页面,做 CSS 替换(Wikiwand),可以做类似 service worker 的网络请求替换或转发(ProxySwitchOmiga),也可以替换掉一些 HTTP 标签来做 AD Block;插件里运行的 JS 还可以通过只提供给插件端 JS 的 chrome 对象,拿到收藏夹往里面加东西或者生成收藏夹树状图,也可以拿到这些按钮的控制权 ↓ 往上面加点击事件监听器。

但这种直接执行插件提供的 JS 实在是太底层了,它可能只能看到页面上干巴巴的 HTMl,根本不知道应用层里,Redux-Saga 运行着数十个协程,Apollo-Client 缓存着七八个 query。如果插件里也维护着自己的状态,那么就会因为「single source of truth」问题导致潜在的竞态条件。良好的前端插件系统不但开放 HTML 等底层信息,也要有合适的模型把应用层暴露给插件端 JS,以便插件能修改 Virtual Dom。
Atom 是一个用起来比较卡的,完全插件化的好看的文本编辑器,它安装后提供的功能是以 77 个官方插件的形式存在的。比如其中的 autocomplete 官方插件,因为不够好用,后来被社区大受好评的 autocomplete-plus 插件替换掉了,这插件系统就非常民主。[1] 只有完善了插件系统,我们的产品才是民有、民治、民享的。
Atom 可以通过 .tree-view 等选择器来选中界面上的 UI 元素,用宽高阴影等特效来美化 Atom 原有的界面。[14],因为 Atom 不再使用 Shadow DOM,所以做到这点变得很容易。
VSCode 出于性能考虑限制了插件能访问的 UI 元素,还将插件分到宿主进程、语言处理分到语言服务器,它出色的性能在打开巨型 JSON 文件和使用 TypeScript 推断类型时显现无疑。此外,VSCode 的开发团队认为如果将 DOM 暴露给插件开发者的话,它们就会和 VSCode 的界面紧密耦合很容易因为 VSCode 的更新而挂掉,他们希望只暴露一些松耦合的东西给插件开发者。
例如资源管理器是可以被插件有限定制的,你可以往资源管理器上加上一个自己的 tab,点开这个 tab 后出来一个列表,在插件里可以返回一个继承自 vscode.TreeItem 的类的实例的列表,从而显示一些定制化的内容。但不管怎么定制,它终归是一个列表。[11]
UserScript
当 Youtube、百度云等网站被我们发现有前端漏洞,可以在 JS 上下点功夫,获得免 VIP 跳过广告、满速下载时,我们可能会把我们发现的漏洞做成一个 UserScript,从而重复利用它。
用户友好的界面
大部分用户是懒于使用「高级功能」的,例如在使用笔记类应用时,只有少数精英用户愿意大量使用 RDF-style 语义标记,而大部分用户只是想用一个友好美观的表单来填写数据,填完了事。
如果让插件有提供个性化 UI 组件的功能,会使用高级功能的工程师用户就能封装出特定场景下使用的表单 UI,造福大量小白用户。[10]
Atom 逐步在暴露给插件开发者的 atom 对象上加入新的函数,来增强开发者对界面做出修改的能力。例如 atom.workspace.getActiveTextEditor().decorateMarker 函数就可以在某个文字块的前面或后面加上内容。 [15]
嵌入包含(Transclusion)
嵌入包含(transclusion)通常是指将一份文档以链接的形式置入另一份文档之中以作为参考文献。这是 MediaWiki 的模板功能的实现基础,能够将同样的内容置入多个不同的文件中,若要编辑该内容时不须个别进行编辑。
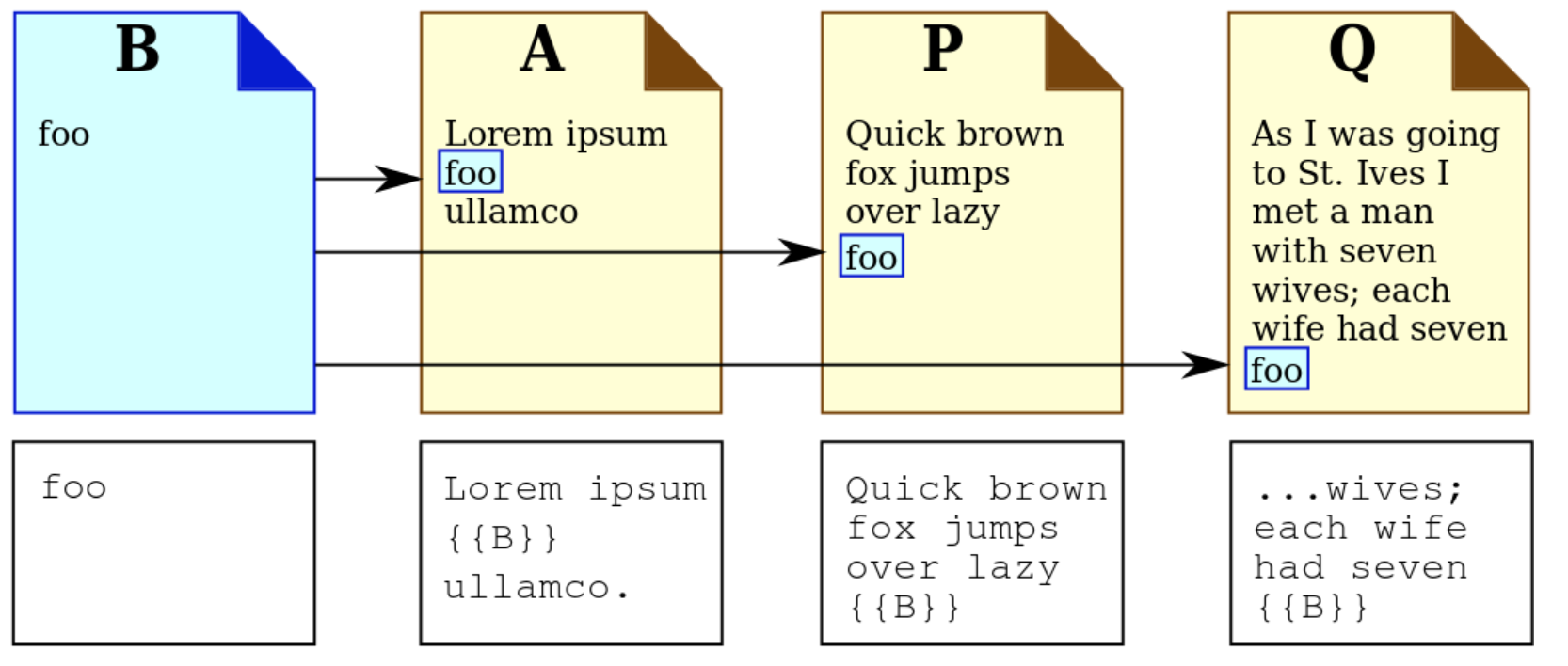
Tiddly Wiki 用它来生成 UI 模板,供其他插件使用,具体还得看 https://tiddlywiki.com/dev/#TiddlyWiki%20Core%20Application 中列出的一些源码,只看介绍的话,觉得没有说清楚。
让插件们知道发生了什么
Wiki 系统有一个 what links here(链入页面),当你在一篇文章里添加了指向另一篇文章的链接,另一篇文章就会注意到这一点,并把你刚写的这篇文章加入它的链入页面。这就像你盯着一个壮汉看,他就感到后脑勺发痒,转过身对你说「你瞅啥」一样。
MediaWiki 有一个任务队列,类似于 Redux,当你添加了指向另一篇文章的链接,这会形成一个消息(类似于 Redux Action),某个监听这个消息的函数就更新你所指页面的「链入页面」。这种消息也用于:1. 在你添加新页面的时候自动更新目录页把你的页面加进去 2. 在你删除页面的时候把所有其他页面上指向已删页面的链接从蓝色变成红色。[8]
上述行为类似于 Redux-Saga 通过监听消息来启动异步操作,例如你通过点击删除按钮,发出了一个删除 Action,一个 Saga 便开始执行,它会调查一下有哪些页面引用了你刚删的页面,并对每个页面启动一个新的更新页面上链接颜色的 Action。当有大于 500 个 Action 被同时发出时,它们会被分成每 500 个一组。[9] 如果你用过 GraphQL,你可能会发现这很类似于 dataloader 这个 npm 包做的事。
VSCode 对于语言服务和 Debug 服务使用 stdin 和 stdout 来和真正处理内容的程序通信,通信内容是一个 JSON。这样语言服务就可以用非 JS 的语言来书写,但坏处是在浏览器中运行的程序没法像 electron 中的程序那样接触到 stdio,这或许可以通过把这类服务做成服务端插件,因而把 stdio 改成 HTTP 来解决,虽然可能会爆慢,不适合一些自动补全等场景。对于可能的延迟问题,VSCode 的做法是让计算可取消,类似 redux-saga 的 takeLatest 或 cancel 的效果。插件会在收到新数据的同时接受到一个 CancellationToken 参数,以便像 IntelliSense 或者 GitLens 之类的插件能得知用户还在继续输入,之前接收到的数据已经作废了还是重新算吧。
与物理世界接触
许多非盈利机构都有爆多文件,他们的志愿者的电脑桌面可能密密麻麻堆满了文件,各种电子表格记录着各种各样的信息,这还比较好办,毕竟开一个支持电脑内所以文件全文搜索的软件就能找到你想要的东西。但许多人事档案是纸质化的,记录志愿者兴趣、住址的单子会经过志愿者转录变成整理好的纸质卡片,就像旧时代的图书馆借书卡一样。
他们可能曾经想过用更牛逼一点的信息管理系统,但这些系统除了学习困难(要求你按照它的设计思路来录入数据)、录入费时以外,还会有很多数据无法纳入系统,或者干脆就没空录入。所以每次他们觉得现在的信息管理系统用得不爽,打算换一个更牛逼的系统,都会在迁移过程中丢掉一大堆数据。[4]
但如果你的插件系统开放了通向物理世界的接口,使用者就有可能通过光学扫描仪、声呐、引力波探测器等物理设备导入他们本无法纳入或懒得录入的数据。
一般来说,反向插件系统做这事比较简单:
假设我们已经实现了一个图像预览的主程序,这个主程序能够实现放大、缩小、旋转、拍照等功能,并且这个主程序已经被发布了。忽然有一天,客户提出这样一个要求,他们手上有一台中控设备,这台设备可以通过串口和电脑相连,恰好这台设备可以发送三个不同的命令(或者更多),然后他们希望可以通过设备上的按键命令控制那个图像预览程序的放大、缩小和旋转。我们可以分析一下,为了不让客户的特殊需求污染了原来程序的设计,只能设计成某种形式的插件系统,并且可以通过配置文件灵活的取消或者启用这个特殊的插件。如果设计成前向插件系统,那么主程序必须实现插件约定的某种接口,如果使用 C/C++实现的话可以使用回调函数或者虚类。一方面,如果插件需要主程序提供的 API 过多,将会让接口约定变得很长;另一方面,如果有另外更多用途的插件需要主程序提供各自不同的 API,这个时候主程序的设计将陷入由插件主导的尴尬境地。如何解决上述(或许还有没有讲到的)问题呢?反向插件系统就是一种很好的选择。首先,反向插件系统要求主程序在接口设计上处于主导地位,主程序公开了什么 API,插件就只能使用什么 API;其次,主程序可以通过归纳对需要公开的接口进行分类,避免上述问题导致的导出重复 API 的可能。 [6]
这种从外部录入数据的接口,没有实时要求的部分(扫描仪输入)可以使用 HTTP API,例如 REST、GraphQL 等,外部程序是独立程序,只是扫描完图像后调用 HTTP API 上传数据而已。
类似 GraphQL 这种带反射功能的协议也可用于构造前向插件系统,例如用户使用第三方网站上传扫描的图像,我们的应用的前向插件系统应该能让用户登陆这个第三方网站的账户,获取 credentials,并扫描 GraphQL API 的字段信息,由字段信息生成一个专门的用户界面让用户能把第三方网站视为一个插件。
使用 Electron 等基于 Chromium 的框架时,我们可以把 Chromium 的 USB 支持 API 转发给开发者,也就是我们使用封装这些 API 的 npm 包(前向插件),并让开发者使用我们暴露的 JavaScript API 作为后向插件。
Tiddly Wiki 在尝试保存用户的改动的时候,会遍历各个 saver 插件(saver tiddler),然后调用它们的 canSave(wiki) 方法,如果返回的是 true,并且 create(wiki) 方法返回了这个插件的一个实例,核心就使用这个 saver 来持久化数据。之所以要先做这个检查,是因为有的插件可能因为物理限制无法使用,比如一个核心插件会尝调用一个叫 Tiddlyfox 的火狐浏览器插件,如果它发现没装这个浏览器插件,它就会返回 false。
可以想象一个连接打印设备的 saver,它会检测物理世界是否有打印机,如果有的话就保存当前笔记到物理世界的一张 A4 纸上,那么如果用户没有安装打印机到他的工作环境中,打印机 saver 的 canSave(wiki) 方法就会返回 false。
更新时的安全问题
如果有一个大家都在用的「material-design」主题插件,突然有人在某个贴吧里发布了它的最新版本,声称新版本增加了不少膜蛤动效,并要求大家保护性反对。所以大家都不顾评论里的警告就去下载安装它,结果这个插件并不是来自之前的开发者,而是另一个恶意开发者,他把用户的文件全部发送到自己的服务器上了。
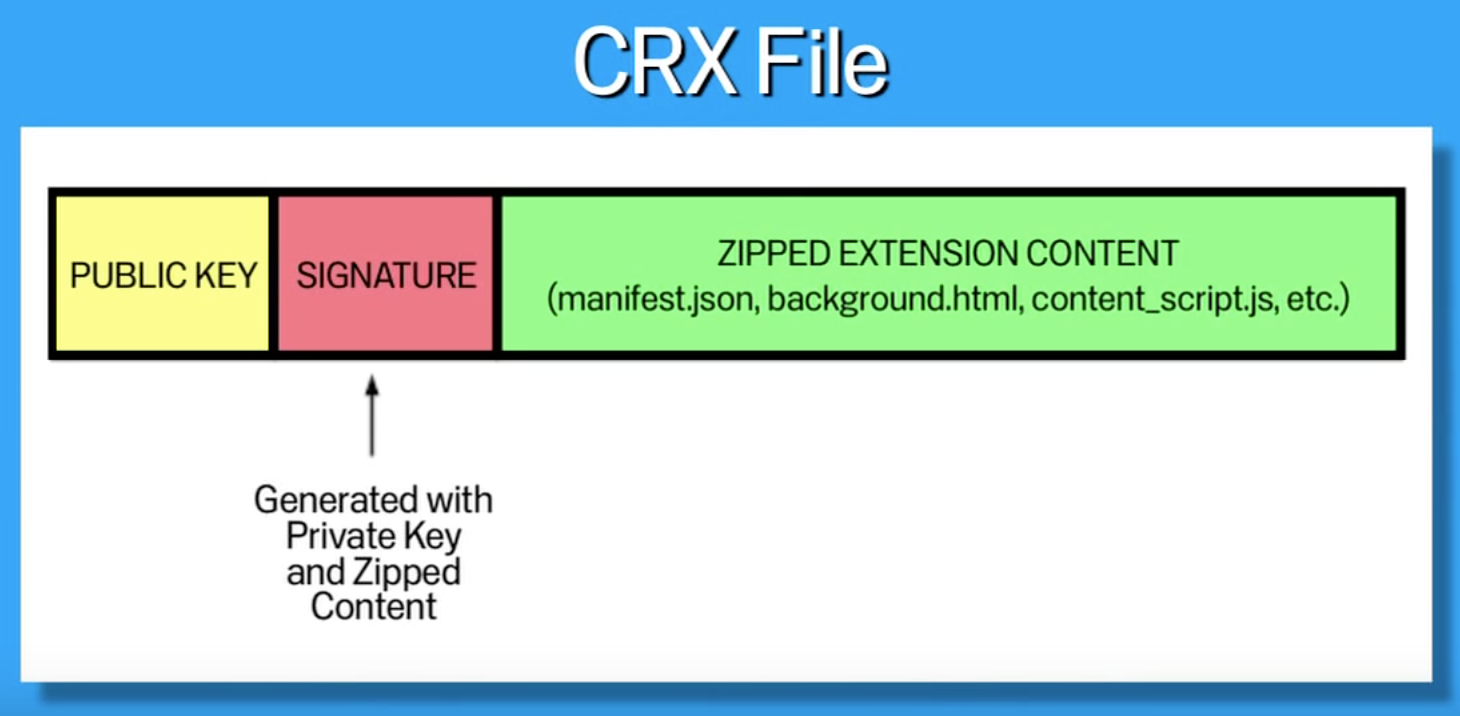
因此用于表明发行者身份是之前的开发者,以及文件内容不是被第三方修改后才发到贴吧上的 signature 就很重要了。
 [7]
Chrome 的插件把主体内容放在一个 zip 压缩包里,并附上开发者公钥、由私钥和压缩包内容生成的 signature,来保障使用者在贴吧上随便下个包也不会下到社会闲散人员恶意篡改的插件。
[7]
Chrome 的插件把主体内容放在一个 zip 压缩包里,并附上开发者公钥、由私钥和压缩包内容生成的 signature,来保障使用者在贴吧上随便下个包也不会下到社会闲散人员恶意篡改的插件。
可交互对象
Rimworld 有一种在前端应用中一般以 SEO 为目的出现的插件类型:Definations,简称为 defs。Defs 是用 XML 写就的定义文件,描述了游戏过程中出现的植物、动物、建筑、武器还有音效、背景音乐等游戏组成部分。 比如下面这个 XML 描述了世界地图上的帐篷:
<?xml version="1.0" encoding="utf-8"?>
<!-- https://github.com/skyarkhangel/Hardcore-SK/blob/master/Mods/Camp/Defs/WorldObjectDefs/WorldObjects.xml -->
<Defs>
<WorldObjectDef>
<defName>CaravanCamp</defName>
<label>caravan camp</label>
<description>A camp.</description>
<worldObjectClass>Nandonalt_SetUpCamp.CaravanCamp</worldObjectClass>
<texture>SetupCamp/Flag</texture>
<expandingIcon>true</expandingIcon>
<expandingIconTexture>SetupCamp/Flag</expandingIconTexture>
<expandingIconPriority>8</expandingIconPriority>
</WorldObjectDef>
</Defs>
而在早些时候,我们为了 SEO 可能会在界面上加上 microdata,比如像这样描述一个有两种口味的冰淇淋:
<div itemscope>
<p>Flavors in my favorite ice cream:</p>
<ul>
<li itemprop="flavor">Lemon sorbet</li>
<li itemprop="flavor">Apricot sorbet</li>
</ul>
</div>
这段数据有其相对应的 JSON-LD 和 RDFa。[17]
在 Rimworld 里游戏开发者提供的主要游戏内容是以一个 core mod 的形式存在的,他们声称虽然这是一个科幻游戏,但你可以用一个中世纪 mod 替换掉 core mod,再下载别的某个开发者提供的武器 mod,启动后游戏还是能正常运行,从中世纪 mod 里随机选取生物生成在地图上,并从第三方武器 mod 里随机取出武器定义,生成出武器分发给生成的敌人。[16] 在一个 mod 内,这些 xml 文件分布在数个文件夹内,分别是可交互物品、科研项目、多语言,此外还有一个文件夹用于存放 C# 编译出的 dll 文件,这些 dll 可以小范围地修改游戏机制。
参考
- Atom 背后的故事
- 如何理解 semantic mediawiki 插件的用途?
- python 插件系统
- 帮助:Semantic Mediawiki
- A Semantic Web for End Users
- 反向(或者后向)插件系统设计
- Google Chrome Extensions: Identity, Signing and Auto Update
- 链入页面如何起作用
- Wikipedia Job Queue
- Schema or not schema
- VSCode 插件:nodeDependencies
- VSCode 插件概念:Contributes
- C9 的插件系统:Architect.js
- Atom Theme System
- Atom Block Decorations
- Modding Rimworld
- microdata
- 精读《插件化思维》
- etherpad 插件系统
- uppy 插件系统
- 个人知识管理系统 TiddlyWiki 架构
- TiddlyWiki 的插件系统
- CKEditor 的插件接口
- 知乎问答
- 山寨 AMD
- 强大的 trilium 笔记管理系统的前后端插件 API
- VSCode 插件开发全攻略
