GraphQL 是一个能表现出数据层次性,适合 React 这种单页应用结构的数据层模型。
FaceBook 发现了 RESTful 数据层模型的不便之处,引领业界通过使用他们开发的 Relay 享受到 GraphQL 带来的 Optimistic Update(点完赞之后不用等网络传输延时直接点亮图标)、Data Diff(你随手发出了一大坨请求,Relay 自动帮你只请求真正需要更新的一小部分数据)、Declarative Data Need(数据需求就声明式地写在 React 组件旁边,前端后台都是声明式的,改需求很好改)。这不是一篇介绍 GraphQL 的文章,是一篇介绍怎么用好 GraphQL 的文章,如果你不是很清楚 GraphQL 的写法,请看我以前写的中文教程(已 TJ)。

Meteor 团队有着很丰富的数据流控制经验,他们发现了 Relay 的不便之处,引领业界通过使用他们开发的 APOLLO 享受到更简洁的接口,阅读到更易懂的教程,而且让人们敢用到生产项目里。

它的书写流程从 UI 开始,这里使用了 HOC,和 Redux、Relay 很像:
// Feed.js
class Feed extends React.Component { // 这是一个显示信息流的 React 组件
constructor() {
super();
}
render() {
const { data, mutations } = this.props; // 从 APOLLO 的 HOC 中传来的数据(data)和更新后台的函数(mutation)
static propTypes = {
data: React.PropTypes.object,
mutations: React.PropTypes.object,
};
return (
<div>
<FeedContent
entries={data.feed || []}
currentUser={data.currentUser} // 绑定数据
onVote={(...args) => mutations.vote(...args)} // 绑定函数
/>
</div>
);
}
}
// 然后声明式地,告诉 APOLLO 你需要什么数据
const FeedWithData = connect({
mapQueriesToProps: ({ ownProps }) => ({
data: { // 上面 const { data, mutations } = this.props 中的 data 就是来自于这里
query: gql`
query Feed($type: FeedType!, $offset: Int, $limit: Int) {
currentUser { # 这个对应于上面的 data.currentUser,也就是说 currentUser 会作为 data 对象的一个 key
login
}
feed(type: $type, offset: $offset, limit: $limit) { # 这个对应于上面的 data.feed
createdAt
commentCount
score
id
postedBy { # 都是经典的 GraphQL 写法
login
html_url
}
vote {
vote_value
}
repository {
name
full_name
description
html_url
stargazers_count
open_issues_count
created_at
owner {
avatar_url
}
}
}
}
`,
variables: {
type: (
ownProps.params &&
ownProps.params.type &&
ownProps.params.type.toUpperCase()
) || 'TOP',
offset: 0,
limit: itemsPerPage,
},
forceFetch: true, // 一般基于 GraphQL 的框架都会自动 cache 获取的数据,因为应用的不同角落可能会用到同一个数据。forceFetch 则表示别 cache
},
}),
//还有你想怎么更新后台数据
mapMutationsToProps: () => ({
vote: (repoFullName, type) => ({ // 上面的 onVote={(...args) => mutations.vote(...args)} 中的 mutations.vote 就是来自这里
mutation: gql`
mutation vote($repoFullName: String!, $type: VoteType!) {
vote(repoFullName: $repoFullName, type: $type) {
score
id
vote {
vote_value
}
}
}
`,
variables: {
repoFullName, // 这些参数就从 mutations.vote(...args) 的 ...arg 中获得
type,
},
}),
}),
})(Feed);
export default FeedWithData;
接下来 APOLLO 会自动处理 Minimize、Augment、Fetch 的部分,也就是说,只要实现告诉 APOLLO 你的服务器地址,它就会自动找出真正需要更新的界面对应的那一小部分请求,处理 GraphQL Schema Decorators,打包请求,发给服务端。
下面再看看服务端怎么回应我们的请求。

先用 express、HAPI、Connect 或 koa 接收一下发来的 JSON 格式的请求:
// server.js
import { GitHubConnector } from './github/connector'; // 取数据用的小弟
import { schema, resolvers } from './schema';
import { makeExecutableSchema } from 'graphql-tools';
const executableSchema = makeExecutableSchema({
typeDefs: schema,
resolvers,
});
app.use(
'/graphql',
apolloExpress(req => {
const gitHubConnector = new GitHubConnector({
clientId: GITHUB_CLIENT_ID,
clientSecret: GITHUB_CLIENT_SECRET,
});
return {
schema: executableSchema,
context: {
user,
Repositories: new Repositories({ connector: gitHubConnector }),
Users: new Users({ connector: gitHubConnector }),
Entries: new Entries(),
Comments: new Comments(),
},
};
})
);
我们传入了 resolvers 和 schema 合体而成的 executableSchema,以及一个 context,executableSchema 描述了我们接收和返回的数据,context 是实际操作数据库的工具。
下面我们来分别看看它们长什么样。
Schema 来自于这个文件,它在比较高的层次上描述了我们接收和返回的数据长什么样:
// schema.js
const schema = [`
enum FeedType { # 先定义数据类型
HOT
NEW
TOP
}
type Query {
# To display the current user on the submission page, and the navbar
currentUser: User
# For the home page, the offset arg is optional to get a new page of the feed
feed(type: FeedType!, offset: Int, limit: Int): [Entry] # 然后把类型作为组件用在别的类型里,就像 React 一样
}
# Type of vote
enum VoteType { # 这是经典的 GraphQL 写法,希望你看得懂
UP
DOWN
CANCEL
}
type Mutation {
# Vote on a repository
vote(repoFullName: String!, type: VoteType!): Entry
}
schema {
query: Query
mutation: Mutation
}
`];
export schema;
resolvers 来自于下面这个对象,我们把它也放在 Schema.js 里,它在比较低的层次上干脏活,实际去数据库取数据的就是它们。之所以它也被放在 Schema.js 里,是因为 schema 定义了获取、改变数据需要什么样格式的输入输出,但它本身没法去取数据对吧,resolvers 就是在 javascript 的层面上实现了这一点。俩兄弟放在一起好参照、修改:
// schema.js
const resolvers = {
Query: {
currentUser(_, __, context) { // 上面 server.js 里, app.use('/graphql', apolloServer((req) => { 那边返回了一个 context ,就会传到这
return context.user;
},
feed(_, { type, offset, limit }, context) {
const protectedLimit = (limit < 1 || limit > 10) ? 10 : limit;
return context.Entries.getForFeed(type, offset, protectedLimit);
},
},
Mutation: {
vote(_, { repoFullName, type }, context) {
if (! context.user) {
throw new Error('Must be logged in to vote.');
}
const voteValue = {
UP: 1,
DOWN: -1,
CANCEL: 0,
}[type];
return context.Entries.voteForEntry( // 这边就是在操作数据库了,所谓 Mutation 就是 CRUD 中的 CUD 三类操作的统称
repoFullName,
voteValue,
context.user.login
).then(() => (
context.Entries.getByRepoFullName(repoFullName)
));
},
},
};
export resolvers;
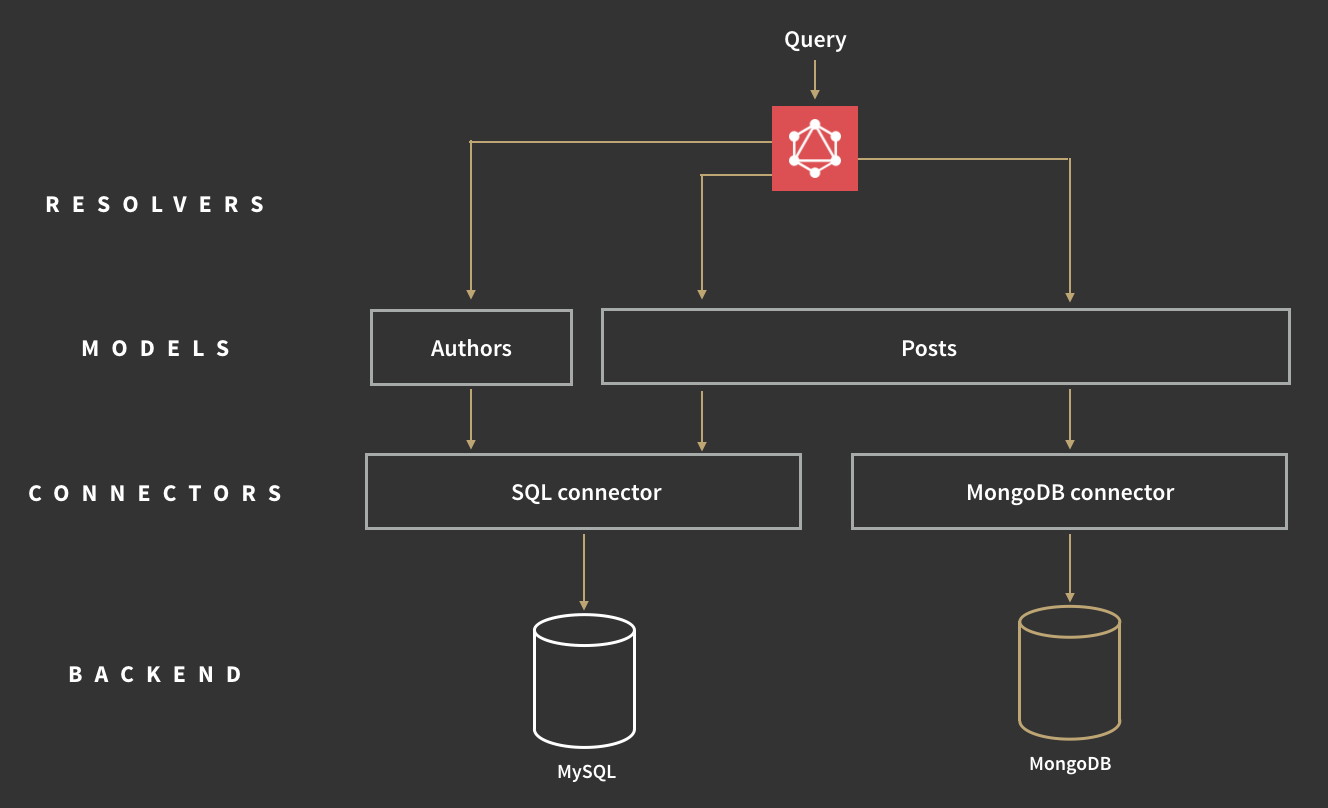
而 Connectors 来自图下面的这个文件,resolveFunctions 通过它来与数据库沟通。
比如说我们项目中用到了 MongoDB 和 MySQL 的话,我们可以用 APOLLO 社区里分享的,别人写的 SQL connector 和 MongoDB connector 来连接数据库,然后在 Authors 和 Posts 两个 Model 里面使用它们,进行再一次抽象,这样在 Schema.js 里我们就不用再关心使用的是什么数据库了,完美解耦。
希望你还记得,我们上面传了一个 context 给 APOLLO 服务器中间件:
// from server.js
context: { // 在秘书取数据的时候传给秘书的档案,也就是在 graphQL 解析的时候传给 resolvers 的一个参数
user,
Repositories: new Repositories({ connector: gitHubConnector }), // Connector 就是数据库驱动,比如你用 Neo4j
Users: new Users({ connector: gitHubConnector }), // 那它就可以是 neo4j-driver 再包装一下的结果,所以 Connector 可以在多个项目之间复用
Entries: new Entries(), // new 出来的 Entries 是 Model,也就是打包好的一堆操作 connector 的函数
Comments: new Comments(), // 在介绍完 schema 和 resolver 之后我们再来看它们
},
关于 Model,在我们使用的示例代码中只用到了 context.Entries.getByRepoFullName(repoFullName) 这一个不带 Connector 的 Model,没用到 Repositories 和 Users 这两个带 gitHubConnector 的 Model,所以我们只好分开介绍一下 gitHubConnector(connector)和 Entries(Model)。
// gitHubConnector.js
export class GitHubConnector {
// connector 一般是一个类
constructor({ clientId, clientSecret } = {}) {
// connector 中会进行一些验证操作,所以要向构造器传入登陆信息或验证令牌等
// ...我想到了一些精彩的验证操作,但空位太小写不下了
this.loader = new DataLoader(this.fetch.bind(this), {
// 然后搞一个 DataLoader
// DataLoader 第一个参数是一个函数,它接受一个 id(或其它能作为主键的东西) ,然后用这个 id 向数据库或 API 请求数据,并 cache 起来
// 它是 Facebook 开发用来配合 GraphQL 后台的包,请看 https://github.com/facebook/dataloader
// The GitHub API doesn't have batching, so we should send requests as
// soon as we know about them
batch: false,
});
}
get(path) {
// 然后在其他更具体的取数据的函数里,用这个 DataLoader 取数据
return this.loader.load(GITHUB_API_ROOT + path);
}
// ... 还有一些我们暂时用不到的函数
}
这个 GitHubConnector 用起来是这样的:
// model.js
export class Repositories {
constructor({ connector }) {
// connector 会被作为参数传给 Model
this.connector = connector;
}
getByFullName(fullName) {
// 然后你再用这个 connector 提供的函数来取数据
return this.connector.get(`/repos/${fullName}`);
}
}
有人可能要问了,这样强行解耦,会不会有一种,钦定的感觉啊?
事实上你完全可以在 resolver 里就直接连接数据库,完全不用模块化地分成几个部分,但这样的话,写来写去的代码啊,就乃衣服。
不过 Connector 这一层一般可以直接用数据库相关的 npm 包:
// model.js
export class Entries {
getByRepoFullName(name) {
// No need to batch
const query = knex('entries') // knex 是一个关系型数据库的连接器,可以看到这边我们并不用自己写一个 Connector,直接用的是 npm 包
.modify(addSelectToEntryQuery)
.where({
repository_name: name,
})
.first();
return mapNullColsToZero(query);
}
}
以上就是 GraphQL Server 里需要写的内容。
由此,我们就了解了 UI Component 和 GraphQL Server 的写法,请看下图:

其余部分就是 APOLLO 的工作了,它将返回的数据放在 Redux 里,然后更新 UI。
如果你正在做一个初期 demo,数据需求快速变动,你可以试试 APOLLO; 如果你正在重构一个大型应用,其数据依赖错综复杂,你也可试试 APOLLO。
